On the Importance of Owning the Smartest AI
An analysis of the global AI infrastructure build-out.
If you have been monitoring the cybersecurity landscape over the past six months, you can see that something important is happening.
We are currently witnessing an unprecedented surge in npm supply-chain attacks, from the March 2026 compromise of the axios package to the May 2026 “Mini Shai-Hulud” campaign that hit packages across the TanStack, Mistral AI and other ecosystems.
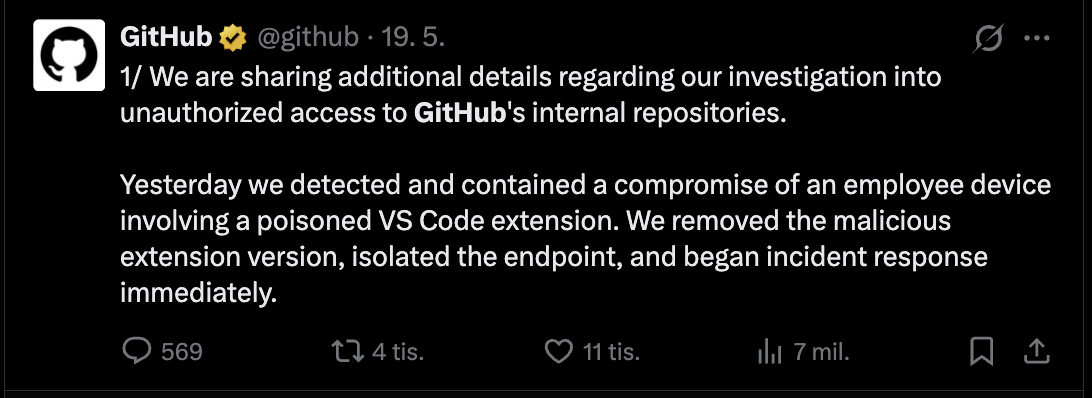
Even GitHub got breached last week.
So you might ask: why is this happening?
Why npm is getting hit
I think we do know the answer. Hackers are adapting AI models to build malware.
And it is not only that. There is much more code being generated, which means much more code is being pushed to GitHub and into production. It is also quite safe to say that a lot of generated code is reviewed less carefully than code used to be reviewed. So the amount of code that can potentially be exploited has exploded.
But it is not only poorly written new code that gets exploited. What is happening in reality is that even very old Linux kernels and code written over the past 30 years can suddenly become easier to attack.
Models are getting good enough
The reason is that we have now figured out that the best LLMs are already smart enough to help find security exploits, vulnerabilities and malware patterns, if someone manages to bypass the classic guardrails. OpenAI and Anthropic do have guardrails, of course, but malicious actors will keep trying to go around them.
This is why npm supply-chain attacks are such a good example. If you install a frontend library through npm, it can pull hundreds of transitive dependencies. If one of those dependencies is infected, you can get compromised through downstream packages you did not even know you were using.
There is a reason why some of the most sensitive government websites look like they are from the 90s. Plain HTML and basic CSS reduce the attack surface and avoid exposing the system to malicious packages.
This is already a huge problem, but it is not the grand problem.
The bigger issue
The bigger problem is that no software is really safe in the same way as before. Historically, serious exploitation required very good cybersecurity engineers. Hackers and attackers were people who studied this for years. Now the barrier is much lower, because people can use frontier models to help them find vulnerabilities and build exploit workflows much faster than they could before.
Of course, it is more nuanced than that. Finding a real zero-day is still difficult. Reliable exploitation is still difficult. But this is where things are heading.
So how do you protect yourself?
Access to the best models
The only way is to have access to the best models yourself. Before you deploy your site or infrastructure, you need to pentest it first. You use the best models with the best attack strategy you can, and you check whether it is possible to find exploits before someone else does.
This brings me to why owning the best models matters.
What is already happening is that many people do not have access to the very best models. Right now, the best public models are already very smart. But the strongest internal systems inside the major AI labs may be even more capable for cybersecurity, coding and pentesting.
The exact internal model names matter less than the access problem. If OpenAI, Anthropic or another frontier lab can decide who gets access to the strongest cyber-capable models, then a European company that does not get access is automatically more vulnerable than someone who does.
You could argue that this is fine for now because the companies that own the best models are trustworthy and would not misuse them. But in the future, these capabilities may become available to more companies, more governments and eventually more hostile groups. Everyone who does not have access to the same level of models, or the infrastructure to run them, becomes more vulnerable.
This is a very big issue when the whole world is moving everything into software and the cloud, from small-business databases all the way to governments and elections.
The transatlantic disparity
Let’s look at the higher-level picture. Why does Europe not have native access to the best AI systems?
The first answer is capital.
There is simply not enough money flowing through the European ecosystem to retain the best talent. Many of the best European AI scientists and engineers work for Anthropic, OpenAI, Google DeepMind, xAI, Meta and other US-based labs. This is not because Europe has no talent. It is almost the opposite. Europe has a lot of talent, but the ecosystem around that talent is weaker.
The second answer is infrastructure.
Europe does not have the same density of hyperscale AI data centers and GPUs as the US. Even if a sovereign European initiative raised the money, it would still need physical access to huge interconnected clusters, cheap power, cooling, networking, storage and the operational talent to run all of it.
When you look at the combined compute power available to OpenAI, Anthropic, xAI, Meta, Google and Microsoft, the scale is very hard to match.
This is why the model race is not only a software race. It is also a physical infrastructure race.
Inside the compute arms race
To understand the infrastructure side, we should look at what is driving the build-out of AI data centers and GPUs.
The easiest place to start is revenue.
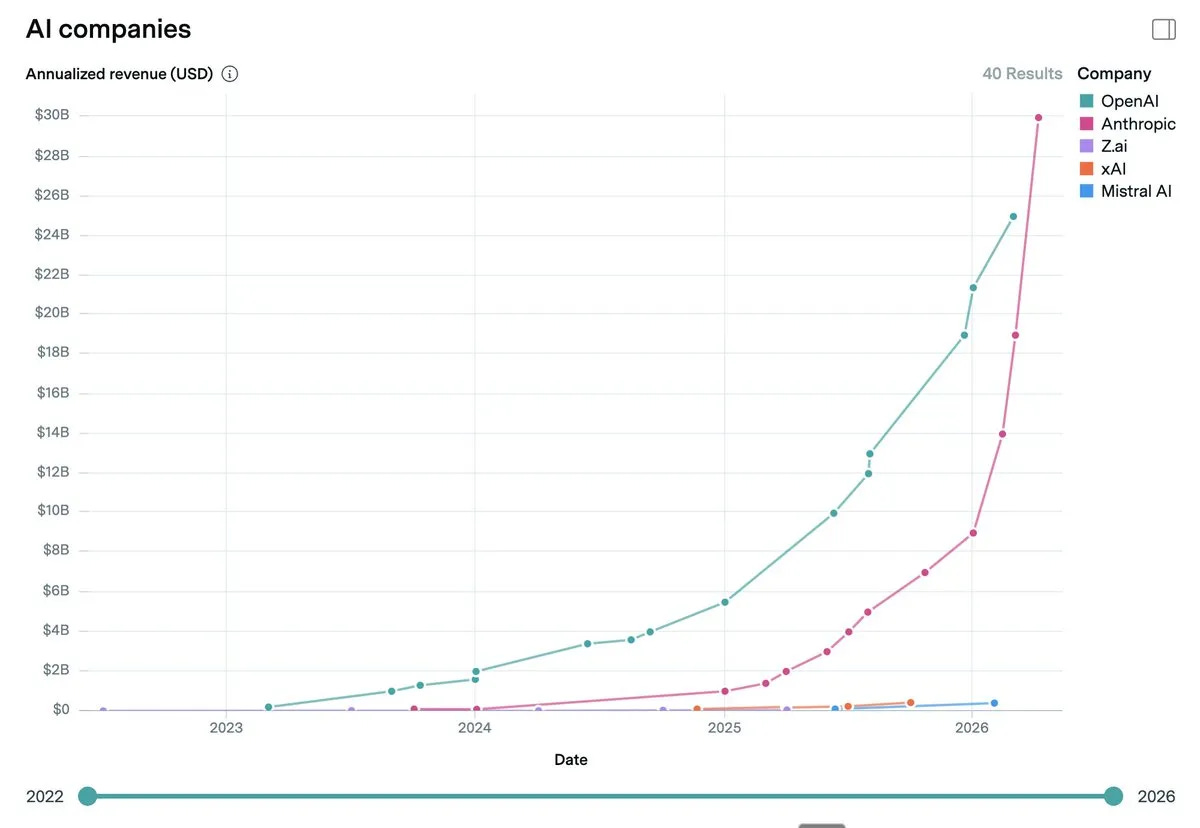
Anthropic revenue growth.
Anthropic has been very successful lately. The main reason, from what I can see, is that Claude Code is getting massively adopted by companies. Around the end of last year, large enterprises and corporations realized that Claude Code exists, and now Anthropic is closing huge deals with companies that want to use it. The important point is that these agentic CLIs are not useful only for developers. Once the pattern works for coding, companies start to ask whether similar agentic tools can work for legal work, finance, operations and other white-collar workflows.
Anthropic passed USD 30B ARR in April 2026, up from around USD 1B in January 2025. That revenue curve is the easiest way to understand why the infrastructure demand is becoming so extreme.
OpenAI is now pushing Codex hard as well.
For a while, Codex felt like a side product. It existed, but it did not feel like the main thing. Then the market started to understand that agentic models and CLIs can be used for much more than coding. The same pattern can move into legal work, finance work, operations, research and normal office work.
Anthropic got there first with Claude Code. OpenAI is now catching up with Codex.
You can see this race happening in real life here in San Francisco. OpenAI is doing everything it can to increase Codex usage. It is burning a lot of money to get people to use the product. In practice, this means subsidizing inference: paying more to run the product than users are paying back, because the priority is adoption.
One very concrete example was the Codex event OpenAI hosted here. I spoke with Sam Altman for a couple of minutes, and we discussed how he successfully stepped up his Twitter posting game, which ultimately helped Codex get much more attention and adoption. Sam also made a pretty clear jab at Anthropic, saying they do not care about developers. It all felt like a very well-calculated marketing strategy to catch up with the hottest product in the field: Claude Code.

Our team with Sam Altman at the OpenAI GPT-5.5 launch party.
It feels like the next huge thing since the original ChatGPT moment. Almost like the second inflection point. The reason is simple: agents are suddenly starting to work.
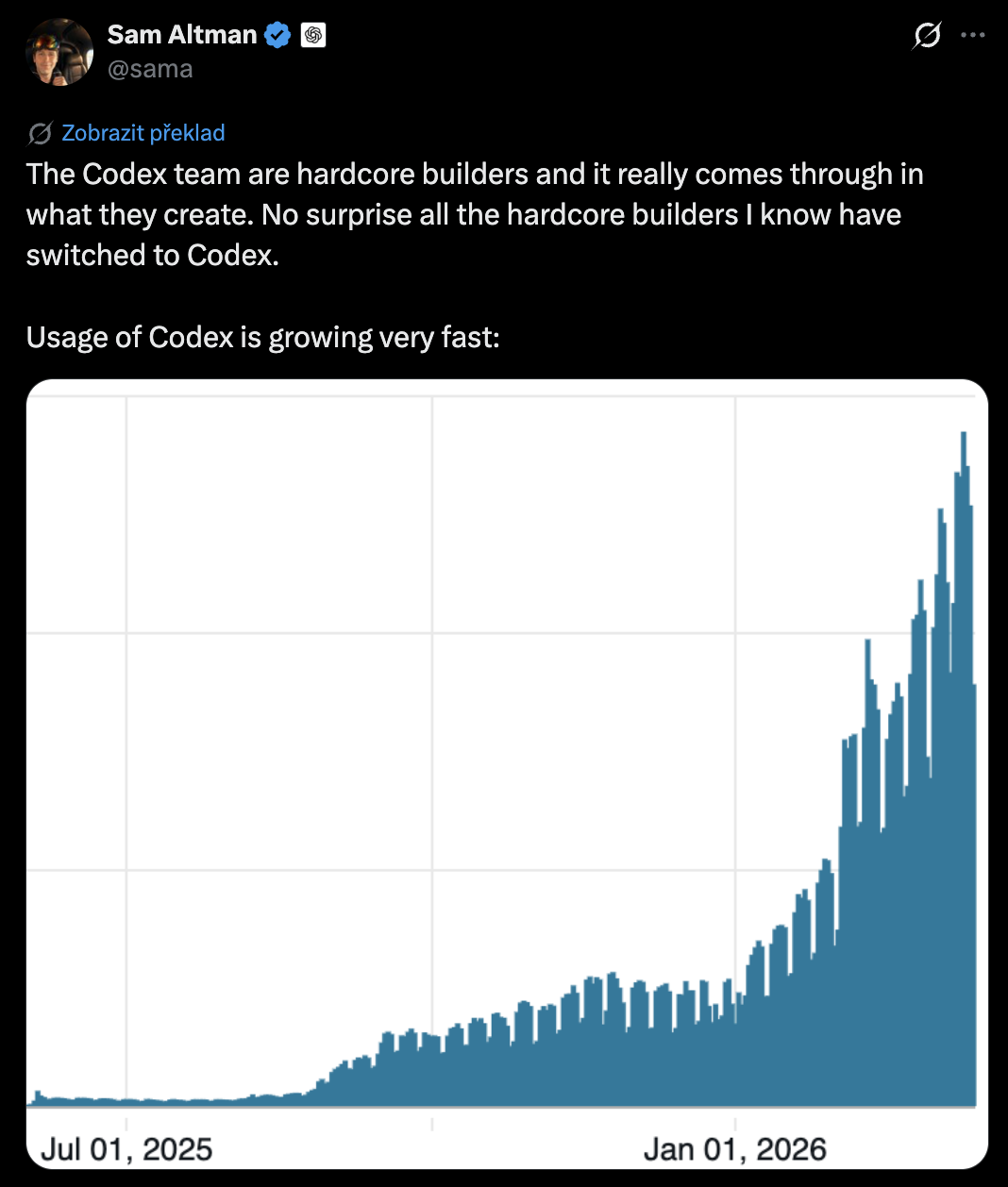
Codex usage growth.
The same race is happening in talent. The most valuable people are the ones who understand how to train models, improve them, and turn research progress into better products. Anthropic has been very successful at hiring that kind of talent, and the compensation is becoming ridiculous. Andrej Karpathy recently joined Anthropic’s pre-training team to work on using Claude to accelerate pre-training research, which is a good example of how intense the competition has become.
There is also a LinkedIn detail here. If you check many people working at Anthropic, their role often just says “Member of Technical Staff.” The reason is that it makes poaching harder, because from the outside you cannot easily tell whether someone is working on pre-training, post-training, inference, infrastructure, product, or something else.
If large enterprises start using these tools every day, inference demand becomes enormous.
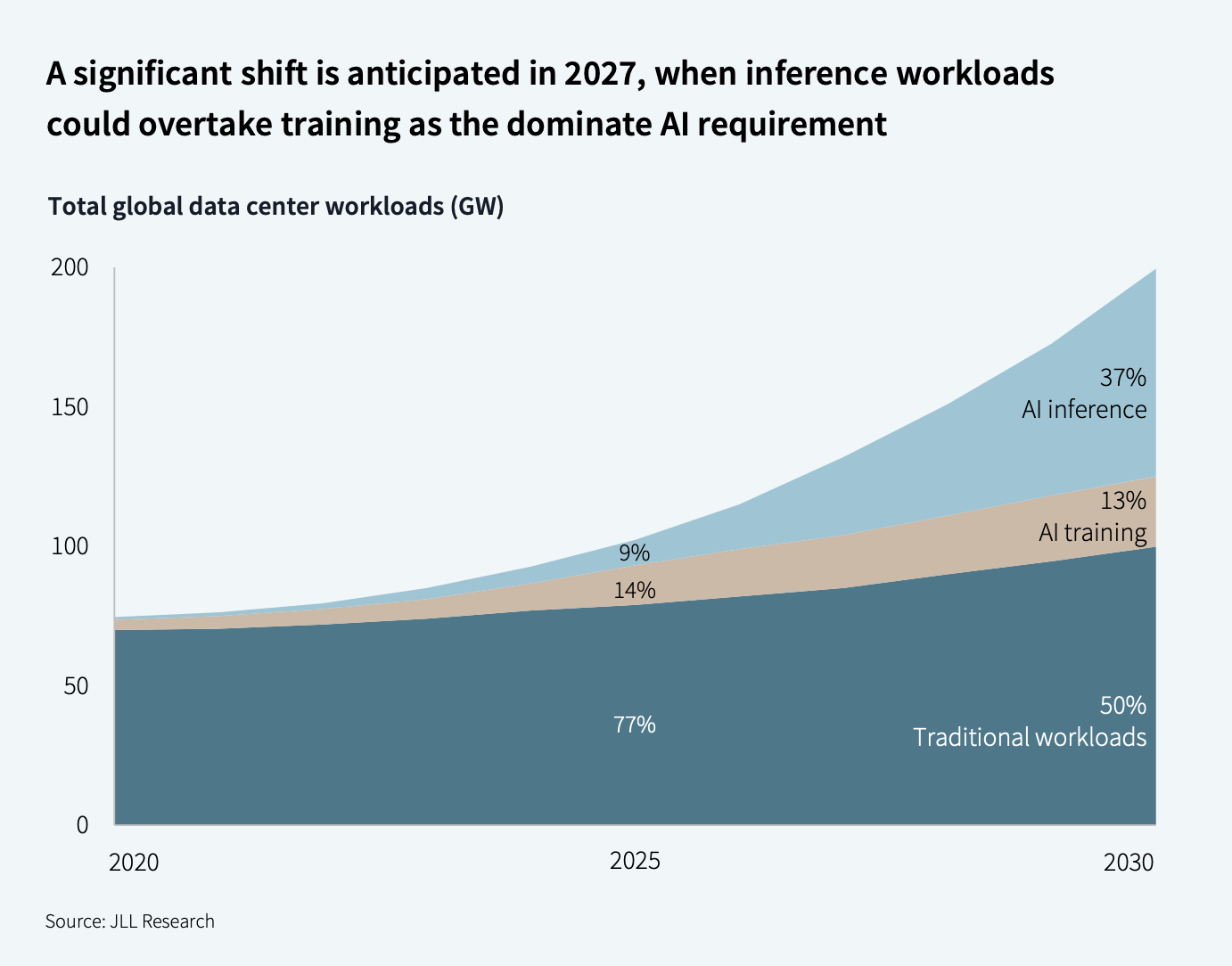
Inference workload growth.
So the largest AI companies are realizing something very simple: if this growth continues, they need a huge amount of compute just to support customers.
Anthropic is a good example. Claude Code became so popular that users ran into tighter limits, overload errors and periodic outages. The better-supported public wording is not that one specific outage was definitely caused by a GPU shortage, but that surging demand strained Anthropic’s compute capacity.
That still supports the same point. Anthropic’s own Claude Code docs describe repeated 529 Overloaded errors as the API being temporarily at capacity across users. Axios reported that surging demand was straining Anthropic’s compute, with users running into tighter limits and periodic outages. And after Anthropic gained access to xAI / SpaceX’s Colossus capacity, Tom’s Hardware reported that Anthropic said the extra capacity would improve the experience for paid Claude users and double Claude Code’s five-hour rate limits.
And then you start to see the big deals.
The Hut 8 / Fluidstack deal is one example. Hut 8 announced a 15-year, 245 MW AI data center lease at its River Bend campus, with USD 7.0B of total contract value over the base term and up to USD 17.7B if renewal options are exercised. Google is also providing a financial backstop.
Another example is Anthropic renting compute from xAI. TechCrunch reported that Anthropic will pay xAI USD 1.25B per month through May 2029 for 300 MW of compute from the Colossus 1 data center near Memphis. The total deal could bring xAI more than USD 40B of revenue.
This may look overpriced. But Anthropic needs the compute to support growth. Otherwise, it cannot keep taking on more customers at the same pace.
This is what I mean by the cost side of the build-out. The demand is real, but the spending is still insane. Everyone is trying to lock in infrastructure before everyone else does.
The AI race is in full swing
In conversations with people in San Francisco and back home, I often hear that AI will start taking jobs at some point in the future.
My usual answer is that the future is already happening.
Layoffs are already happening. People are already struggling to find jobs, especially in the US corporate sector. Meta is a good example. Recent reporting says Meta planned to cut around 8,000 jobs, or about 10% of its workforce, while continuing to spend heavily on AI infrastructure.
The point is that this is not theoretical anymore. Companies are already reallocating more money toward compute, models, automation and AI infrastructure.
When I compare San Francisco to Europe, San Francisco feels two to three years ahead in AI adoption and public sentiment. In Europe, public sentiment is not as split yet. People are not really scared yet that AI will take their jobs. In San Francisco, it feels very real.
Self-driving cars are everywhere. Waymos are a normal part of the city. On our first day, we saw with our own eyes that some taxi drivers are not happy about them. We got blocked by a taxi driver and boxed in while riding in a Waymo. You can feel that some people really do not like what is happening, which makes sense.

Waymo robotaxis in San Francisco.
The same thing is starting to happen with data centers. Public sentiment is shifting. A lot of people are against building more data centers, and data center build-out is becoming part of the political discussion. In the US, this is already showing up inside Democratic politics: some Democrats are targeting data centers over energy and water use, Sanders and AOC introduced a bill to pause new AI data centers until safeguards are in place, and Axios reported that some Democratic governors who previously pushed AI data center projects are now backing away because of voter backlash.
European public sentiment is not as split on AI yet.
But I think it will happen in Europe in the next two to three years as well.
The USD 3 trillion infrastructure build-out
What does the physical build-out of AI infrastructure actually look like, and will Europe catch up?
According to JLL’s 2026 Global Data Center Market Outlook, the industry has entered an AI infrastructure supercycle.
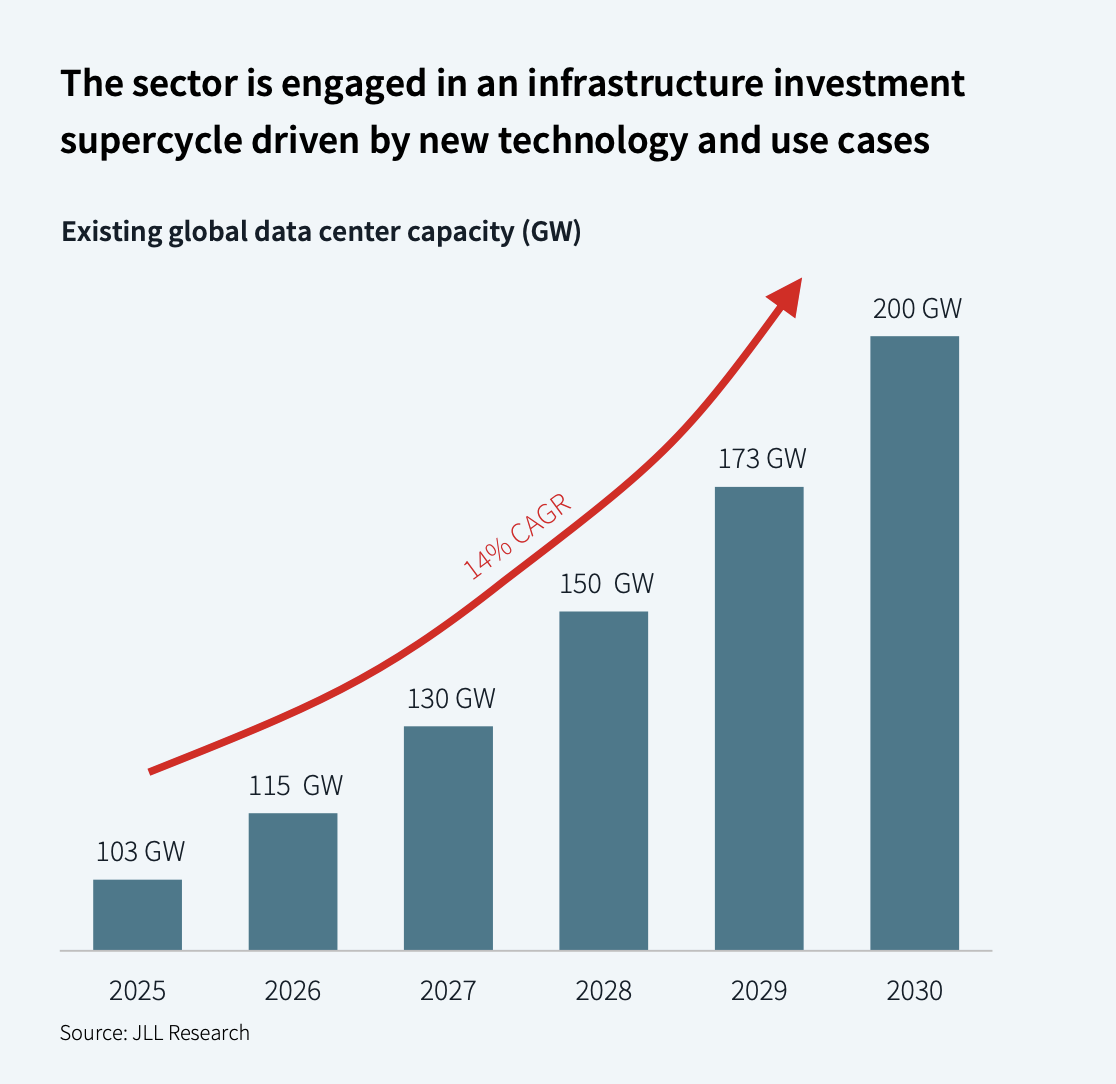
AI infrastructure supercycle.
JLL projects nearly 100 GW of new data center capacity from 2026 to 2030. That would roughly double global data center capacity. JLL also estimates up to USD 3T in total spending by 2030.
The split is important.
Around USD 1.2T is real estate asset value: land, shells, power infrastructure, substations, grid connections, cooling and construction. But tenants may spend another USD 1T to USD 2T on the IT fit-out: GPUs, servers, networking and supporting equipment.
In other words, the building is expensive, but the compute inside the building is even more expensive.
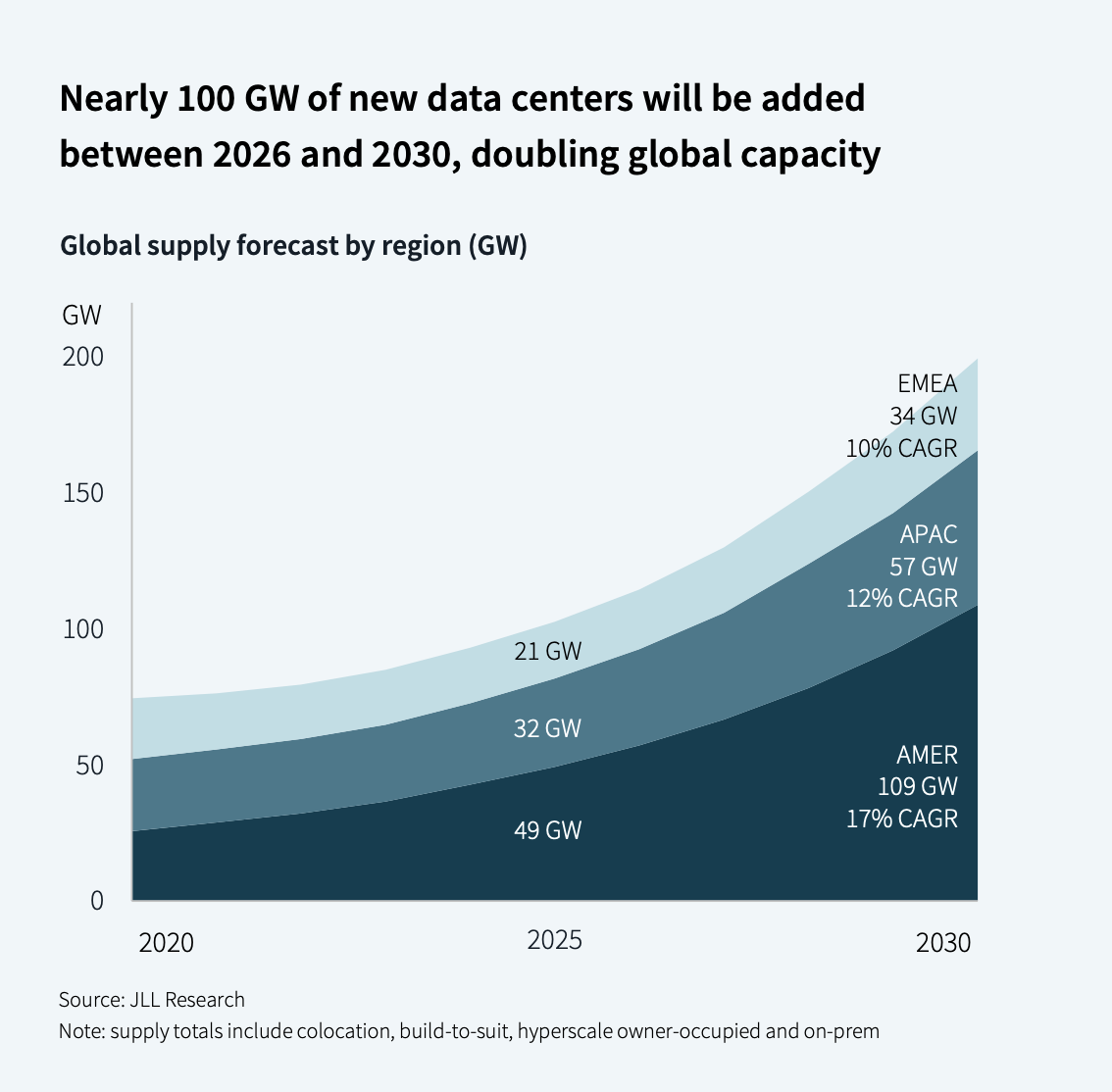
Projected global data center capacity growth.
JLL expects global data center capacity to grow from roughly 100 GW today to around 200 GW by 2030. In EMEA, it expects about 13 GW of new supply. That is a lot. But it still does not mean Europe catches up with the US.
From our vantage point at Era Compute, where we partner closely with European data center operators, the pipeline of new projects is large. Many operators are planning major capacity expansions over the next few years.
But Europe is structurally different from the US.
In the US, the market is increasingly dominated by very large, centralized AI campuses. Some projects are moving toward hundreds of megawatts or even gigawatt-scale planning. In Europe, the market is more fragmented. We see many strong projects, but they are often staged, local, and dependent on very specific power availability, grid connection, permitting and customer commitments.
You see 10 MW, 20 MW, 50 MW projects. You see operators trying to secure power first, then customers, then financing, then construction. It is not impossible. It is just slower and more fragmented than the American hyperscale build-out.
Traditional hubs like Frankfurt, London, Amsterdam and Paris are also dealing with saturated power grids and high electricity costs. Because of this, more interesting projects are appearing in the Nordics, where there is cheaper industrial power, renewable energy, cooler climate and better cooling economics.
One project I personally find really cool is Lefdal Mine Datacenter in Norway.
Instead of building a normal above-ground warehouse, Lefdal uses a former olivine mine inside a mountain. The site has huge underground halls, renewable power, fjord-water cooling and expansion potential up to hundreds of megawatts.

Lefdal Mine Datacenter in Norway.
This is what makes data centers interesting. When people hear “data center”, they imagine one giant gray building full of servers. But AI infrastructure can also mean old industrial sites, mines, hydro regions, Nordic power surplus and places where the physics of power and cooling are better.
The GPU capacity dynamic
Beneath the macro infrastructure numbers, there is a very curious mismatch in the GPU capacity market.
Right now, there is huge demand for short-term compute. Startups, AI labs and mid-market operators are constantly looking for clusters of NVIDIA chips like H100s and B300s.

NVIDIA B300 cluster.
The issue is that most of this demand is short term. A company may need a cluster for one month, three months, or even next week because it wants to train a new model, support a new customer, or cover an unexpected spike in inference. We see this constantly: people reach out saying they need compute ASAP. Physical data centers, however, do not work on those timelines.
Constructing high-density AI data centers requires massive upfront capital. This is usually funded with debt and project finance. To raise that debt, lenders want contracted revenue. They want to see that a customer has signed a long-term offtake or colocation lease before the data center gets built.
So operators need 2- to 5-year commitments, and sometimes much longer. The Hut 8 / Fluidstack lease is 15 years. From the data center side, that makes sense. From the startup side, it feels impossible.
This creates a gridlock:
- startups want compute now
- startups want flexibility
- data centers need long-term commitments
- lenders want signed contracts
- GPU buyers are scared of being locked into overpriced capacity if the market cools or GPU prices fall
That last point is critical.
If you sign a 5-year fixed-price lease for GPUs or colocation, you absorb market-price risk. The GPUs probably will not become useless; demand is too high for that. The real risk is that the AI infrastructure market cools, competition tightens, or GPU prices fall, and you are still legally bound to pay above-market rates for capacity that looked reasonable when you signed.
This is why many companies want flexibility, but flexibility is expensive. If you buy spot or on-demand GPU capacity from neoclouds, you pay a premium. If you are willing to sign a longer reserved contract, you can usually get a better price. The tradeoff is clear: pay more for flexibility, or take more risk and get better unit economics.
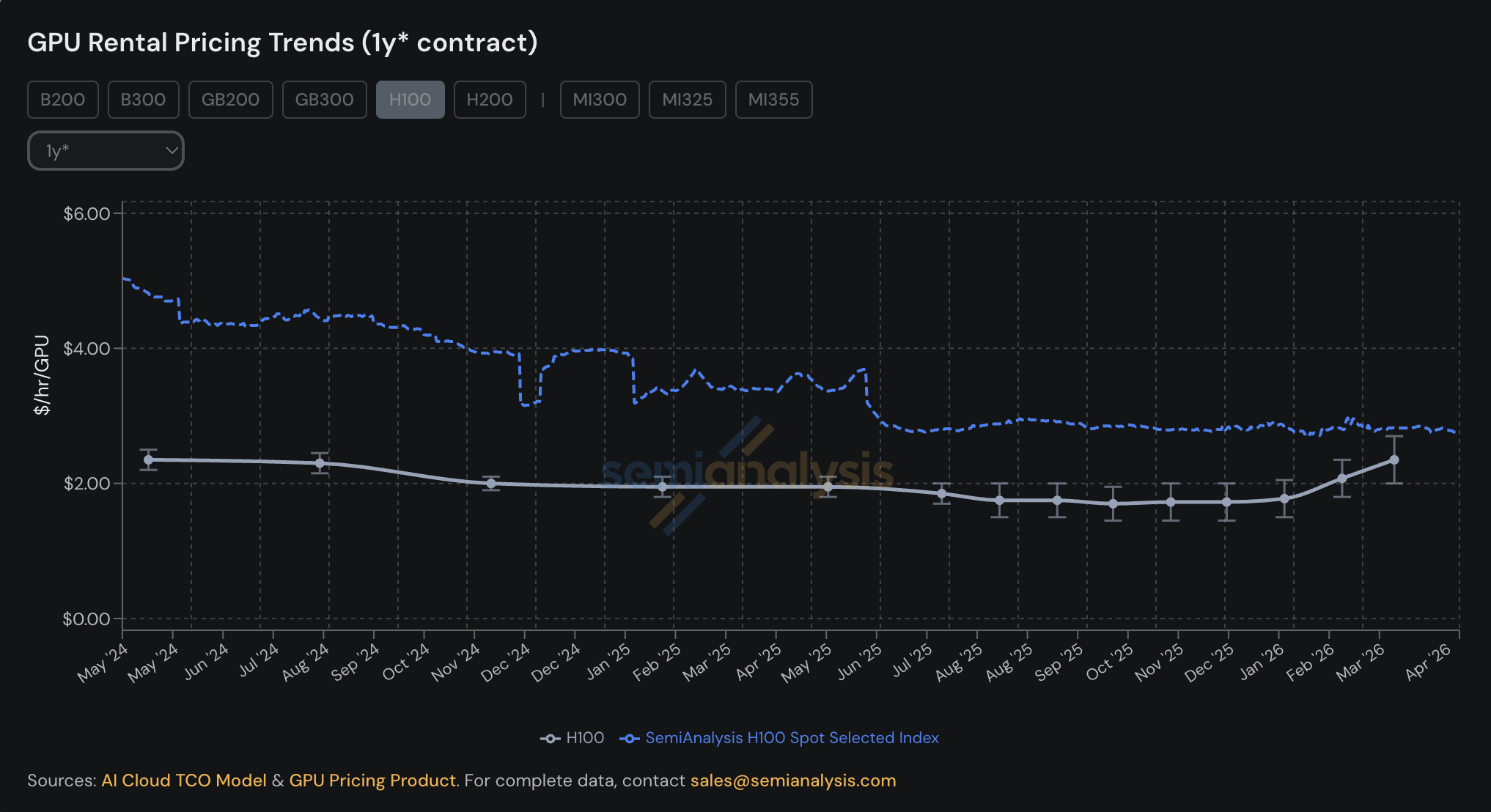
SemiAnalysis H100 rental pricing trends.
Right now, getting large compute capacity in the next few months is borderline impossible. You may find a few megawatts here and there, or a smaller cluster, but a serious contiguous cluster with the right GPUs, network, storage and power is very difficult to secure on short notice. Any company that knows it will need GPUs for inference or training has to decide whether to stay flexible and risk not getting capacity, or reserve capacity early and risk overpaying later.
One thing we observe for sure is that the global GPU crunch is very real. The biggest players know this, which is why they are investing large amounts of money into reserving as much capacity for themselves as they can. OpenAI, Anthropic, xAI, Meta, Google, Microsoft, CoreWeave and others are not waiting for the market to become comfortable. They are reserving power, data centers, GPUs and long-term contracts now.
For smaller players, this creates a difficult question. If they know they will need GPUs for inference or training, they have to decide whether to stay flexible and risk not getting capacity, or commit early and take the risk that the market changes later.
The investor outlook
The infrastructure supercycle has not gone unnoticed by traditional capital. We are now seeing a massive pivot from commercial real estate firms and institutional investors trying to make the ultimate “picks and shovels” play in the hottest market on the planet.
Their focus has shifted because the defining narrative of 2026 is that AI’s biggest bottleneck is no longer only models or chips. The true constraint is raw power generation. The US power grid simply cannot keep up with hyperscale demand, with interconnection queues in major data center hubs now stretching five to seven years. The speed of AI development is moving in weeks, while public utilities move in decades.
This gridlock has forced the industry into a scramble for alternative, behind-the-meter generation, driving a surge of investment into Small Modular Reactors, existing nuclear facilities and power-heavy industrial sites. Hyperscalers realize that long-term AI scaling requires dedicated, industrial-level power. Otherwise, the public grid becomes the ceiling.
The end of limitless compute
You can see the reality of this constraint in how the AI labs themselves are changing their business models. For years, AI was treated like traditional cloud software: pay as you go, with the assumption that capacity was practically infinite.
That era is over.
Just this month, OpenAI launched a new enterprise offering called Guaranteed Capacity. Rather than selling only flexible, on-demand API access, OpenAI is now asking enterprise customers to sign one- to three-year commitments to lock in compute access. OpenAI’s own page says customers can choose 1-3-year commitments, with discounts increasing based on annual commitment. Sam Altman framed the reasoning very directly: customers increasingly want certainty on capacity, and as models get better, the world will be capacity-constrained for some time.

OpenAI Guaranteed Capacity.
When the creator of the world’s most famous AI model starts selling compute like a scarce, multi-year telecom contract, it confirms that infrastructure is the ultimate ceiling. OpenAI is trading discounts for long-term revenue visibility, which helps fund the massive upfront physical build-outs and power purchases required to keep the models running.
Buying the grid
To see how this thesis plays out in financial markets, look at Leopold Aschenbrenner, the former OpenAI researcher whose hedge fund, Situational Awareness LP, ballooned to roughly USD 13.7B by Q1 2026.
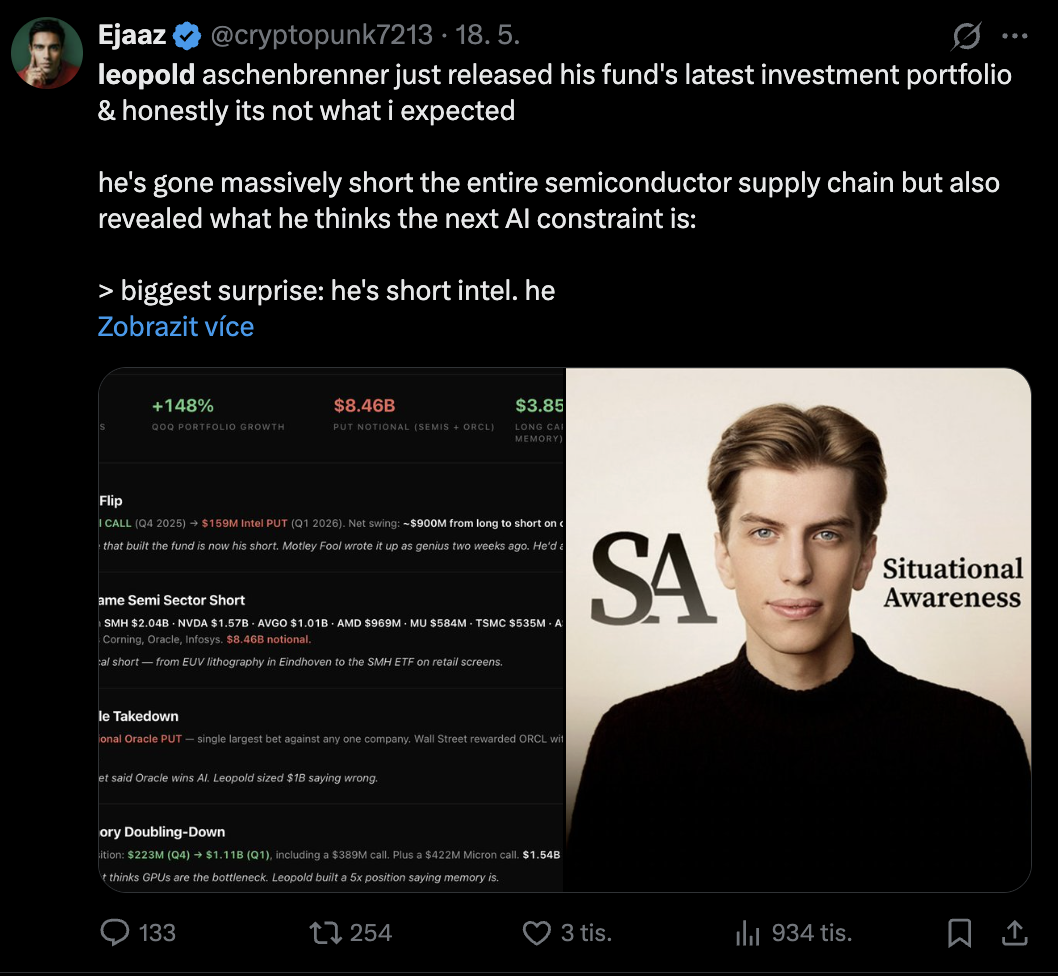
Leopold is one of the biggest celebrities in today’s investment world.
His latest 13F filing reveals a sweeping, contrarian portfolio restructure. Public breakdowns of the filing show a massive options hedge against the semiconductor layer, while the long side increasingly targets the physical constraints of AI. His long positions include alternative energy providers like Bloom Energy and Bitcoin miners like CleanSpark and IREN. Why? Because these operations already hold the exact high-capacity grid connections, land and power contracts that AI hyperscalers desperately need.
The smartest money recognizes a simple truth: software and silicon are fiercely competitive and highly cyclical, but the concrete, steel and dedicated gigawatts required to run them are durable physical realities that cannot be coded into existence. Capital is no longer just chasing the chips; it is hedging against them to buy the power grid.
Sources
- Microsoft Security Blog, “Mitigating the Axios npm supply chain compromise”: https://www.microsoft.com/en-us/security/blog/2026/04/01/mitigating-the-axios-npm-supply-chain-compromise/
- OX Security, “Shai-Hulud, Here We Go Again: 170+ Packages Hit Across npm & PyPi”: https://www.ox.security/blog/shai-hulud-here-we-go-again-170-packages-hit-across-npm-pypi/
- Google Cloud Blog, “GTIG AI Threat Tracker: Advances in Threat Actor Usage of AI Tools”: https://cloud.google.com/blog/topics/threat-intelligence/threat-actor-usage-of-ai-tools/
- The AI Corner, “Anthropic USD 30B ARR, Passed OpenAI Revenue 2026”: https://www.the-ai-corner.com/p/anthropic-30b-arr-passed-openai-revenue-2026
- Axios, “Anthropic’s growing pains mount ahead of OpenAI showdown”: https://www.axios.com/2026/04/23/anthropic-openai-showdown
- TechCrunch, “Anthropic will pay xAI USD 1.25 billion per month for compute”: https://techcrunch.com/2026/05/20/anthropic-will-pay-xai-1-25-billion-per-month-for-compute/
- Hut 8, “Hut 8 Signs 15-Year, 245 MW AI Data Center Lease at River Bend Campus”: https://canada.hut8.com/resources/press-releases/hut-8-signs-15-year-245-mw-ai-data-center-lease-at-river-bend-campus-with-total-contract-value-of-usd7-0-billion
- Axios, “Meta to lay off 8,000 as part of AI efficiency push”: https://www.axios.com/2026/04/23/meta-layoffs-ai-efficiency-push
- The Guardian, “Bernie Sanders and AOC introduce bill to pause building of new datacenters”: https://www.theguardian.com/us-news/2026/mar/25/datacenters-bernie-sanders-aoc
- JLL, “2026 Global Data Center Market Outlook”: https://www.jll.com/en-us/insights/market-outlook/data-center-outlook
- Business Norway, “Lefdal Mine Datacenter is a large-scale data centre in a deep Norwegian mine”: https://businessnorway.com/solutions/leftdal-mine-datacenter-large-scale-data-centre-in-a-deep-norwegian-mine
- SemiAnalysis, AI Cloud TCO Model & GPU Pricing Product: https://semianalysis.com/
- 13F.info, “Situational Awareness LP Q1 2026 13F”: https://13f.info/13f/000204572426000008-situational-awareness-lp-q1-2026
- OpenAI, “Guaranteed Capacity”: https://openai.com/business/guaranteed-capacity/
- Mliu92 / Wikimedia Commons, “Waymo robotaxis, San Francisco” (CC BY-SA 3.0): https://commons.wikimedia.org/wiki/File:Waymo_robotaxis,_San_Francisco.jpg
{kind=link}